따릉이 사용자 관련 데이터들을 이용하여 한 시간 뒤 사용자 수를 예측해보도록 하자.
가장 먼저 데이터를 불러오고 전처리하는 과정을 가지도록 한다.
Library & Data
|
1
2
3
|
import pandas as pd
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor
|
cs |
이번 예제에서는 의사결정트리와 랜덤 트리를 사용을 할 것이다.
사용할 판다스 패키지와 의사결정 트리, 랜덤 트리 모델을 불러오도록 한다.
데이터 불러들이기
|
1
2
3
|
train = pd.read_csv('/content/train.csv')
test = pd.read_csv('/content/test.csv')
submission = pd.read_csv('/content/submission.csv')
|
cs |
pd.read_csv()를 이용하여 데이터를 들러오도록 한다.
Exploratory Data Analysis (EDA) - 탐색적 자료 분석
pd.DataFrame.head()
pd.DataFrame.head()를 통하여 데이터셋이 어떻게 이루어져 있는지 살펴보도록 한다.
|
1
|
train.head()
|
cs |
괄호를 비우게 되면 상위 5개가, 괄호안에 숫자를 넣게 되면 넣은 수만큼 데이터를 볼 수 있다.
|
1
|
test.head()
|
cs |
train데이터와 test 데이터를 비교해 보면 데이터의 개수가 1개 차이가 나는 것을 알 수 있다.
이는 구하고자 하는 한시간 뒤 사용자의 수가 train 데이터에는 적재되어 있지만 test데이터에는 적재되어 있지 않기 때문이다.
우리는 이제 이것을 예측해야 한다.
pd.DataFrame.info()
pd.DataFrame.info()를 이용하여 데이터 셋의 정보에 대하여 알아보도록 하자.
|
1
|
train.info()
|
cs |
비어 있지 않은 값(non-null)은 몇 개인지, column의 type은 무엇인지 알 수 있다.
이때 type의 종류는 int, float, object등등이 있다.
다음은 위 코드를 실행한 결과이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 715 entries, 0 to 714
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 715 non-null int64
1 hour 715 non-null int64
2 hour_bef_temperature 714 non-null float64
3 hour_bef_precipitation 714 non-null float64
4 hour_bef_windspeed 714 non-null float64
5 hour_bef_humidity 714 non-null float64
6 hour_bef_visibility 714 non-null float64
7 hour_bef_ozone 680 non-null float64
8 hour_bef_pm10 678 non-null float64
9 hour_bef_pm2.5 679 non-null float64
dtypes: float64(8), int64(2)
memory usage: 56.0 KB
|
cs |
pd.DataFrame.describe()
pd.DataFrame.describe()를 이용하여 숫자형 column들의 기술 통계량을 알 수 있다.
여기서 기술 통계량이란 해당 colum을 대표할 수 있는 통계 값들을 의미한다.
기술 통계량의 종류에는 아래의 예들이 있다.
- count: 해당 column에서 비어 있지 않은 값의 개수
- mean: 평균
- std: 표준편차
- min: 최솟값 (이상치 포함)
- 25% (Q1): 전체 데이터를 순서대로 정렬했을 때, 아래에서 부터 1/4번째 지점에 있는 값
- 50% (Q2): 중앙값 (전체 데이터를 순서대로 정렬했을 때, 아래에서 부터 2/4번째 지점에 있는 값)
- 75% (Q3): 전체 데이터를 순서대로 정렬했을 때, 아래에서 부터 3/4번째 지점에 있는 값
- max: 최댓값 (이상치 포함)
딥러닝에서 모든 데이터를 바탕으로 학습을 진행하는 것은 자원이 많이 필요하며 오히려 학습에 불필요한 영향을 끼칠 수 있기 때문에 이를 잘 정제하는 것이 중요하다.
|
1
|
train.describe()
|
cs |
다음은 코드를 실행한 결과이다.
|
1
2
3
4
5
6
7
8
9
|
id hour hour_bef_temperature hour_bef_precipitation hour_bef_windspeed hour_bef_humidity hour_bef_visibility hour_bef_ozone hour_bef_pm10 hour_bef_pm2.5 count
count 1459.000000 1459.000000 1457.000000 1457.000000 1450.000000 1457.000000 1457.000000 1383.000000 1369.000000 1342.000000 1459.000000
mean 1105.914325 11.493489 16.717433 0.031572 2.479034 52.231297 1405.216884 0.039149 57.168736 30.327124 108.563400
std 631.338681 6.922790 5.239150 0.174917 1.378265 20.370387 583.131708 0.019509 31.771019 14.713252 82.631733
min 3.000000 0.000000 3.100000 0.000000 0.000000 7.000000 78.000000 0.003000 9.000000 8.000000 1.000000
25% 555.500000 5.500000 12.800000 0.000000 1.400000 36.000000 879.000000 0.025500 36.000000 20.000000 37.000000
50% 1115.000000 11.000000 16.600000 0.000000 2.300000 51.000000 1577.000000 0.039000 51.000000 26.000000 96.000000
75% 1651.000000 17.500000 20.100000 0.000000 3.400000 69.000000 1994.000000 0.052000 69.000000 37.000000 150.000000
max 2179.000000 23.000000 30.000000 1.000000 8.000000 99.000000 2000.000000 0.125000 269.000000 90.000000 431.000000
|
cs |
pd.DataFrame.groupby()
pd.DataFrame.groupby()는 저번 시간에 다루었으므로 넘어가도록 하자.
|
1
|
train.groupby('hour').mean()
|
cs |
위의 코드를 실행하게 되면 hour별로 개체들을 묶고 각 colum별로 평균값을 묶는 것을 말한다.
|
1
|
train.groupby('hour').mean()['count']
|
cs |
위의 코드를 실행하게 되면 hour별로 개체들을 묶고 count값의 평균값을 출력을 하게 된다.
|
1
|
train.groupby('hour').mean()['count'].plot()
|
cs |
위의 코드를 실행하게 되면 hour별로 개체들을 묶고 count 값의 평균값들을 바탕으로 그래프를 그리게 된다.
다음은 위의 코드를 실행했을때 나오는 그래프이다.
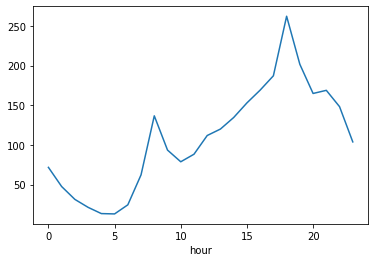
그래프 그리기
그렇다면 이제 그래프를 그리는 즉 시각화를 하는 방법에 대하여 알아보도록 하자.
파이썬에서 그래프는 import matplotlib.pyploy를 통해 불러오고 plt.plot()를 이용하여 그래프를 그릴 수 있다.
() 안에 여러 가지를 입력해서 그래프의 속성을 변경할 수 있다.
다음은 그래프의 속성들 나타낸 것이다.
색깔
문자열약자
| blue | b |
| green | g |
| red | r |
| cyan | c |
| magenta | m |
| yellow | y |
| black | k |
| white | w |
마커
마커 의미
| . | 점 |
| o | 원 |
| v | 역삼각형 |
| ^ | 삼각형 |
| s | 사각형 |
| * | 별 |
| x | 엑스 |
| d | 다이아몬드 |
선
문자열 의미
| - | 실선 |
| -- | 끊어진 실선 |
| -. | 점+실선 |
| : | 점선 |
다음부터는 이를 활용한 예제이다.
|
1
2
|
plt.plot(train.groupby('hour').mean()['count'],'go:')
plt.grid()
|
cs |
plt.grid()를 그리게 되면 그래프에 그래프를 그릴 수 있다.
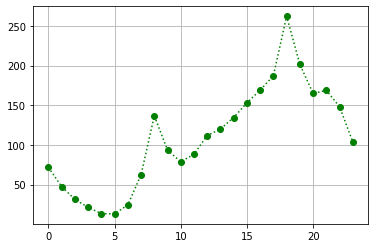
|
1
|
plt.plot('hour', 'count', '*', data = train)
|
cs |
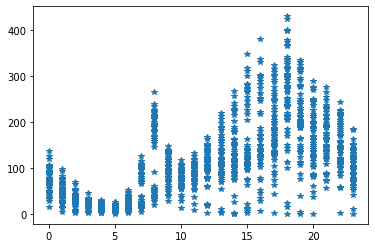
plt.title(label,fontsize)
plt.title()을 이용하여 그래프의 제목을 생성할 수 있다.
plt.xlabel(label,fontsize)
plt.xlabel()을 이용하여 그래프의 x축 이름을 설정할 수 있다.
plt.ylabel(label, fontsize)
plt.ylabel()을 이용하여 그래프의 y축 이름을 설정 할 수 있다.
plt.axvline(x, color)
plt.axvline()을 통하여 x축을 가로지르는 세로선을 생성할 수 있다.
plt.text(x,y,s,fontsize)
plt,text()를 이용하여 원하는 위치에 텍스트를 생성할 수 있다.
|
1
2
3
4
5
6
7
8
9
10
|
plt.plot(train.groupby('hour').mean()['count'],'go-')
plt.grid()
plt.title('count by hours', fontsize=15)
plt.xlabel('hour', fontsize = 15)
plt.ylabel('count', fontsize =15)
plt.axvline(8,color ='r')
plt.axvline(18, color = 'r')
plt.text( 8,120,'go work', fontsize = 10)
plt.text( 18,240,'leave work', fontsize = 10)
|
cs |
위의 코드를 실행하면 다음과 같은 그래프가 나오게 된다.

상관계수
다음으로 상관계수에 대하여 알아보도록 하자.
상관계수란 두 개의 변수가 같이 일어나는 강도를 나타내는 수치를 말한다.
상관계수의 특징으로는
- 1에서 1 사이의 값을 지닌다.
- -1이나 1인 수치는 현실 세계에서 관측되기 힘든 수치이다.
- 분야별로 기준을 정하는 것에 따라 달라지겠지만, 보통 0.4 이상이면 두 개의 변수 간에 상관성이 있다고 이야기한다.

그렇다면 여러분들을 이것을 읽고 상관계수와 인과관계에 대하여 비슷한 것이라고 생각할 수 있다.
하지만 두 가지는 엄연히 다르다.
이에 대하여 알아보도록 하자.

- 선글라스 판매량이 증가함에 따라, 아이스크림 판매액도 같이 증가하는 것을 볼 수 있다.
- 하지만 선글라스 판매량이 증가했기 때문에 아이스크림 판매액이 증가했다고 해석하는 것은 타당하지 않습니다.
- 선글라스 판매량이 증가했다는 것은 여름 때문이라고 볼 수 있으므로, 날씨가 더워짐에 따라 선글라스 판매량과 아이스크림 판매액이 같이 증가했다고 보는 것이 타당할 것이다.
pd.DataFrame.corr()
pd.DataFrame.corr()을 통하여 각 속성별 상관관계를 알 수 있다.
corr은 correlation coefficient의 줄임말이다.
|
1
|
train.corr()
|
cs |
위의 코드를 실행하면 다음과 같은 결과가 나오는 것을 알 수 있다.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
id hour hour_bef_temperature hour_bef_precipitation hour_bef_windspeed hour_bef_humidity hour_bef_visibility hour_bef_ozone hour_bef_pm10 hour_bef_pm2.5 count
id 1.000000 -0.010901 -0.000029 -0.056267 -0.003353 -0.017948 0.008950 0.055234 -0.025510 0.003545 -0.002131
hour -0.010901 1.000000 0.407306 0.021646 0.462797 -0.329612 0.176491 0.390188 -0.035907 -0.061229 0.626047
hour_bef_temperature -0.000029 0.407306 1.000000 -0.097056 0.375618 -0.496088 0.197417 0.541228 -0.003830 -0.078665 0.619404
hour_bef_precipitation -0.056267 0.021646 -0.097056 1.000000 0.022746 0.276481 -0.217155 -0.062461 -0.051266 0.004742 -0.163985
hour_bef_windspeed -0.003353 0.462797 0.375618 0.022746 1.000000 -0.433012 0.252092 0.520526 0.010176 -0.199113 0.459906
hour_bef_humidity -0.017948 -0.329612 -0.496088 0.276481 -0.433012 1.000000 -0.592244 -0.421047 -0.108106 0.167736 -0.471142
hour_bef_visibility 0.008950 0.176491 0.197417 -0.217155 0.252092 -0.592244 1.000000 0.101899 -0.403277 -0.644989 0.299094
hour_bef_ozone 0.055234 0.390188 0.541228 -0.062461 0.520526 -0.421047 0.101899 1.000000 0.113015 0.017313 0.477614
hour_bef_pm10 -0.025510 -0.035907 -0.003830 -0.051266 0.010176 -0.108106 -0.403277 0.113015 1.000000 0.489558 -0.114288
hour_bef_pm2.5 0.003545 -0.061229 -0.078665 0.004742 -0.199113 0.167736 -0.644989 0.017313 0.489558 1.000000 -0.134293
count -0.002131 0.626047 0.619404 -0.163985 0.459906 -0.471142 0.299094 0.477614 -0.114288 -0.134293 1.000000
|
cs |
각 값들을 보면 앞서 말했던 상관관계의 특징들이 나타나는 것을 볼 수 있다.
하지만 위의 결과 값이 눈에 잘 들어오지 않아 파악하기가 어렵다.
이를 시각화할 수 있는 방법에 대하여 알아보자.
seaborn.heatmap
seaborn.heatmap을 사용하면 상관계수 값에 대하여 계산을 하고 이를 시각화하여 나타낼 수 있다.
|
1
2
3
|
import seaborn as sns
plt.figure(figsize = (12, 12))
sns.heatmap(train.corr(), annot = True)
|
cs |
위의 코드를 실행하면 다음과 같은 그래프를 얻을 수 있다.

데이터 전처리
이제 데이터 전처리를 해보도록 하자
Data Cleaning & Pre-Processing
pd.Series.isna()
pd.Series.isna()를 이용하여 결측지 여부를 확인해보도록 하자.
데이터 값에 결측지면 True를 아니면 False를 반환한다.
|
1
|
train.isna().sum()
|
cs |
위의 코드에서. sum()을 해준 이유는 데이터 값이 많기 때문에 모든 값을 합쳐서 결측지의 개수를 구하기 위함이다.
위의 코드를 실행하게 되면 다음과 같은 결과가 나오게 된다.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
id 0
hour 0
hour_bef_temperature 2
hour_bef_precipitation 2
hour_bef_windspeed 9
hour_bef_humidity 2
hour_bef_visibility 2
hour_bef_ozone 76
hour_bef_pm10 90
hour_bef_pm2.5 117
count 0
dtype: int64
|
cs |
위의 결과를 보게 되면 몇몇 개의 데이터가 결측값이 있는 것을 볼 수 있다.
그렇다면 hour_bef_temperature의 결측값에 대하여 보도록 하자.
|
1
|
train[train['hour_bef_temperature'].isna()]
|
cs |
위의 코드를 실행하게 되면 다음과 같은 결과가 나오게 된다.
|
1
2
3
|
id hour hour_bef_temperature hour_bef_precipitation hour_bef_windspeed hour_bef_humidity hour_bef_visibility hour_bef_ozone hour_bef_pm10 hour_bef_pm2.5 count
934 1420 0 NaN NaN NaN NaN NaN NaN NaN NaN 39.0
1035 1553 18 NaN NaN NaN NaN NaN NaN NaN NaN 1.0
|
cs |
데이터를 분석할 때 결측값이 있다는 것은 프로그램이 학습을 진행할 때 제대로 이루어지지 않을 수 있다. 그렇기 때문에 이러한 결측값을 제대로 채워주는 것이 중요하다.
그러면 hour_bef_temperatured의 결측값을 채워보도록 하자.
이번에는 위의 결측값을 평균값을 통하여 채워보도록 하자.
|
1
2
|
train.groupby('hour').mean() ['hour_bef_temperature'].plot()
plt.axhline(train.groupby('hour').mean() ['hour_bef_temperature'].mean())
|
cs |
위의 코드를 실행하게 되면 다음과 같은 결과가 나오게 된다.

pd.DataFrame.fillna()
pd.DataFrame.fillna()를 이용하여 결측값들을 채워보도록 하자.
|
1
|
train.groupby('hour').mean()['hour_bef_temperature']
|
cs |
시간을 토대로 그룹을 묶고 hour_bef_temperature의 평균을 구해보도록 하자.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
hour
0 14.788136
1 14.155738
2 13.747541
3 13.357377
4 13.001639
5 12.673770
6 12.377049
7 12.191803
8 12.600000
9 14.318033
10 16.242623
11 18.019672
12 19.457377
13 20.648333
14 21.234426
15 21.744262
16 22.015000
17 21.603333
18 20.926667
19 19.704918
20 18.191803
21 16.978333
22 16.063934
23 15.418033
Name: hour_bef_temperature, dtype: float64
|
cs |
이제 각 값들의 평균값을 알았으니 결측값들을 채워보도록 하자.
|
1
|
train['hour_bef_temperature'].fillna({934:14.788136,1035:20.926667}, inplace = True)
|
cs |
위의 코드를 실행하게 되면 934행에는 14.788136의 값을 1035행에는 20.926667의 값이 들어가게 된다. inplace 값을 true로 해준 이유는 값을 채워준 후 값을 저장하기 위해서이다.
Ture로 해 주지 않으면 채워진 값이 저장되지 않는다.
|
1
|
train.isna().sum()
|
cs |
값을 채워준 후 결측지가 채워졌는지 확인하기 위해 위의 코드를 실행하게 되면
|
1
2
3
4
5
6
7
8
9
10
11
12
|
id 0
hour 0
hour_bef_temperature 0
hour_bef_precipitation 2
hour_bef_windspeed 0
hour_bef_humidity 2
hour_bef_visibility 2
hour_bef_ozone 76
hour_bef_pm10 90
hour_bef_pm2.5 117
count 0
dtype: int64
|
cs |
위의 결과를 통하여 결측값이 제대로 채워졌다는 것을 확인할 수 있다.
이러한 방법을 이용하여 다른 결측값들도 채워주도록 한다.
이상으로 데이터 전처리하는 과정에 대하여 알아보았다.
다음에는 이 데이터를 바탕으로 모델을 만들고 값들을 예측해 보도록 하자.
'인공지능 > 기존예제' 카테고리의 다른 글
| 따릉이 사용자 수 예측하기_모델 생성 및 학습 (0) | 2021.08.09 |
|---|---|
| 타이타닉승객들의 생존률 예측하기_모델 생성 및 학습 (0) | 2021.08.07 |
| 타이타닉승객들의 생존률 예측하기_데이터 전처리 (2) | 2021.08.04 |



댓글